
elektronik-news.com
10
'21
Written on Modified on
Graphcore News
Graphcore stellt IPU-POD128 und IPU-POD256 Systeme mit bis zu 64 PetaFLOPS KI-Rechenleistung vor
Der europäische KI-Chiphersteller Graphcore hat mit dem IPU-POD128 und dem IPU-POD256 zwei neue KI-Systeme vorgestellt, die die Stärken und Vorteile der von Grund auf für Scale-Out Anwendungen entwickelten Graphcore-Architektur voll ausspielen. Mit 32 PetaFLOPS beim IPU-POD128 und 64 PetaFLOPS beim IPU-POD256 bieten die neuen Systeme eine überragende KI-Rechenleistung für Supercomputer-Umgebungen.

Die neuen Graphcore KI-Systeme ermöglichen ein schnelleres Training großer Transformer-basierter Sprachmodelle, Large-Scale KI-Inferenzberechnungen und die Erforschung neuester KI-Modelle wie GPT und GNN. Durch Aufteilung der Systeme in kleinere, flexible vPODs können mehrere KI-Entwickler Zugriff auf die Graphcore IPUs (Intelligence Processing Units) erhalten. Die neuen Graphcore KI-Systeme eignen sich damit insbesondere für Cloud-Hyperscaler, wissenschaftliche Rechenzentren und Unternehmen mit großen KI-Teams in Branchen wie der Finanz- oder Pharmaindustrie.
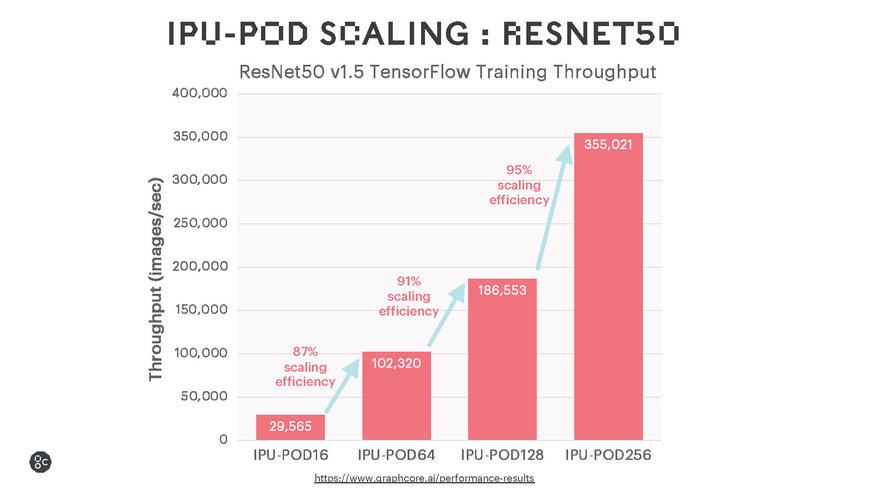
Die Ergebnisse bei Ausführung gängiger Sprach- und Bilderkennungsmodelle zeigen ein beeindruckendes Leistungsverhalten bei KI-Training Workloads und eine hocheffiziente Skalierbarkeit. Dazu dürfte die Leistung durch Softwareoptimierungen noch weiter zu steigern sein.
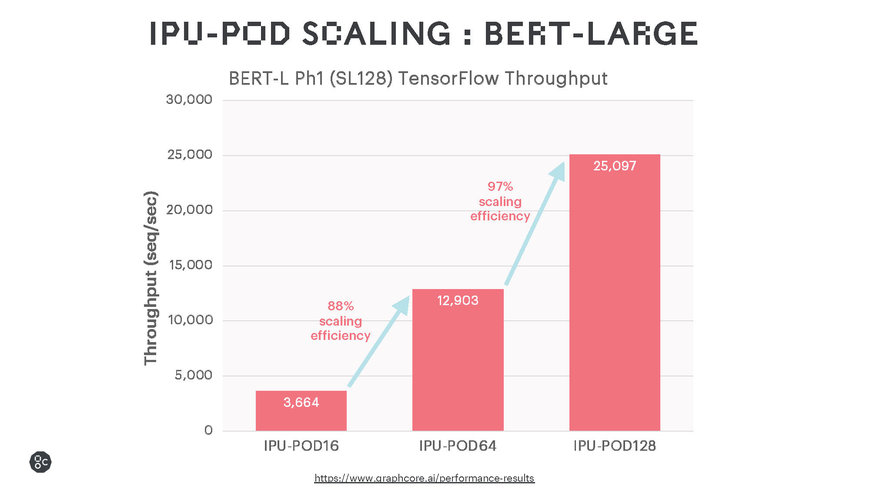
Die Graphcore IPUs bieten aufgrund ihres On-Chip Memory eine ausgezeichnete Leistung für traditionelle große MatMul-Modelle wie BERT und ResNet-50. Darüber hinaus unterstützen sie auch allgemeinere Berechnungsarten, die die Effizienz von Sparse-Multiplikationen und Fine-Grained Berechnungen erhöhen. Die EfficientNet-Modellfamilie profitiert in hohem Maße davon, aber auch verschiedene KI-Modelle für maschinelles Lernen, die nicht auf klassischen neuronalen Netzen basieren, zum Beispiel GNN (Graph Neural Networks).
Die IPU-POD128 und IPU-POD256 Systeme unterstützen Standard-Frameworks wie TensorFlow, PyTorch, PyTorch Lightning, Keras, Paddle Paddle, Hugging Face, ONNX und HALO sowie Standard-Tools und -Protokolle wie OpenBMC, Redfish DTMF, IPMI over LAN, Prometheus und Grafana. So können die neuen Graphcore KI-Systeme reibungslos in bestehende Rechenzentrumsumgebungen integriert werden und Nutzer die zusätzliche KI-Rechenleistung sofort produktiv in ihrer bekannten Softwareumgebung nutzen.
„Wir freuen uns sehr, die neuen IPU-POD128 und IPU-POD256 Systeme von Graphcore in unser Atos ThinkAI Portfolio aufzunehmen. So können wir unseren Kunden helfen, ihre Fähigkeiten und ihr Leistungsspektrum zur Erforschung und zum Einsatz größerer und innovativerer KI-Modelle in vielen Bereichen wie der akademischen Forschung, der Finanzindustrie, dem Gesundheitswesen, der Telekommunikation und dem Consumer-Internet schneller und wirksamer einzusetzen“, sagte Agnès Boudot, Senior Vice President, Head of HPC & Quantum bei Atos.
Zu den ersten Kunden, die die neue IPU-POD128 Plattform implementierten, gehört der koreanische Technologiegigant Korea Telecom (KT). Das Unternehmen profitiert bereits jetzt von der zusätzlichen Rechenkapazität.
„KT ist das erste Unternehmen in Korea, das einen Hyperscale-KI-Service bereitstellt. Dabei kommen die IPU-Systeme von Graphcore in einer dedizierten hochdichten KI-Zone innerhalb unseres Rechenzentrums zum Einsatz. Zahlreiche Unternehmen und Forschungsinstitute nutzen gegenwärtig diesen Service für ihre Forschung, Proof-of-Concept Studien oder führen Tests auf den Graphcore IPUs durch. Zur kontinuierlichen Unterstützung der steigenden Marktnachfrage nach hochskalierbaren KI-HPC-Umgebungen führten wir in Zusammenarbeit mit Graphcore ein Upgrade unserer IPU-POD64 Systeme auf ein IPU-POD128 System durch, um so das Angebot unseres Hyperscale-KI-Service für unsere Kunden zu erweitern. Davon versprechen wir uns eine Erhöhung unserer KI-Rechenleistung auf 32 PetaFLOPS. So können künftig noch mehr Kunden die Spitzentechnologie für KI-Berechnungen von KT für Trainings- und Inferenz-Workloads großer KI-Modelle nutzen“, sagte Mihee Lee, Senior Vice President, Cloud/DX Business Unit, KT.

Skalierbar und flexibel
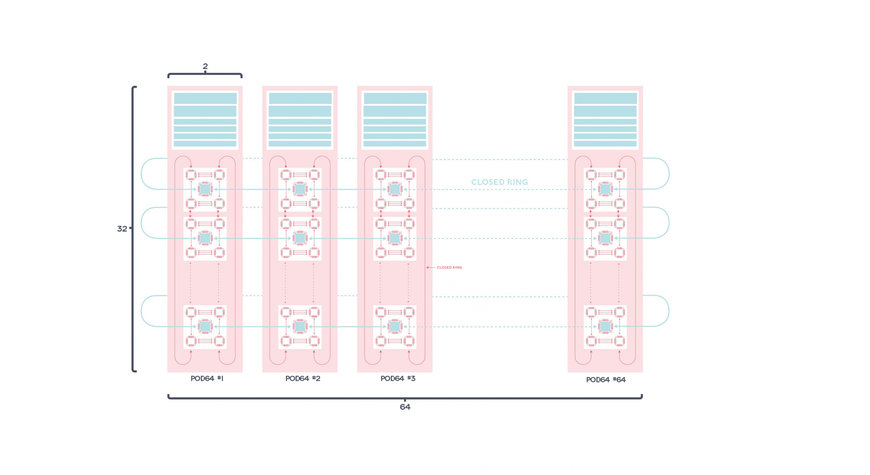
Wie bei anderen Graphcore IPU-POD-Systemen auch bedeutet die Disaggregation von KI-Rechenleistung und Servern, dass die IPU-POD128 und IPU-POD256 Systeme weiter optimiert werden können, um maximale Leistung für verschiedene KI-Workloads bereitzustellen und die Gesamtbetriebskosten (TCO) bestmöglich zu optimieren. Beispielsweise könnte ein NLP-fokussiertes System mit nur zwei Servern auskommen, während datenintensivere Prozesse, wie zum Beispiel Computer-Vision-Tasks, eher von einer Konfiguration mit acht Servern profitieren würden.
Darüber hinaus können auch die angebundenen Storage-Systeme für bestimmte KI-Workloads optimiert werden. Die Storage-Anbieter DDN, Pure Storage, Vast Data und WekaIO unterstützen Graphcore KI-Systeme mit zertifizierten Referenzarchitekturen.
Verfügbarkeit
Die Graphcore IPU-POD128 und IPU-POD256 Systeme sind ab sofort über die Graphcore-Partner Atos, Boston und Megware in der DACH-Region lieferbar und werden auch als Cloud-Service angeboten. Dazu bietet Graphcore ein umfangreiches Schulungs- und Supportpaket an, das es Kunden ermöglicht, die neuen KI-Server schon in kürzester Zeit produktiv einzusetzen.
Systemspezifikationen

www.graphcore.ai
Fordern Sie weitere Informationen an…
